Releases¶
Release 4.5.1¶
This is a minor release that adds missing include files to the distribution (thanks to jcfp for the bug report #573). See the changelog 4.5.1 (2026-03-27) for details.
Release 4.5¶
This release improves Unicode support in re2c.
The internal generator for Unicode include files and tests is now based directly on the official files from unicode.org (previously it was based on the Haskell charset library). It has been updated to the latest Unicode 17.0.0 standard.
New include files have been added for Unicode properties (include/unicode_properties.re) and blocks (include/unicode_blocks.re).
Case-insensitive string literals now use Unicode case mapping for UTF8, UTF16, UTF32 and UCS2 encodings.
See the full changelog for details: 4.5 (2026-03-23).
Release 4.4¶
This release adds generalized end-of-input symbol $.
It is no longer a special rule – it can be used in regular expressions as
part of a normal rule, and it works with all end-of-input handling methods
regardless of the re2c:eof configuration.
The implementation of generalized end-of-input symbol $ is based on a new
API primitive YYEND and the corresponding syntax configuration
code:yyend. The meaning of YYEND is the logical end of input. This
differs from the physical end of input described by YYLIMIT and
YYLESSTHAN – the latter may include padding that was not part of the
original input. If YYFILL is disabled, code:yyend has a default
definition identical to YYLESSTHAN, so the user does not need to explicitly
define YYEND. Otherwise, if YYFILL is enabled, code:yyend does not
provide a default definition and delegates to the user-defined YYEND.
This change breaks backwards compatibility in cases when there are conflicting
$ rules, as they now have position-based precedence like other normal rules.
Hopefully such cases are rare, and the users have been alerted by the
-Wdeprecated-eof-rule warning in release 4.3.
See the changelog: 4.4 (2025-12-20).
Release 4.3.1¶
This is a minor release that fixes bugs: #560 (allow conditions that have no rules except for default rule), #561 (use unsigned character type in C/C++ examples) and most importantly #564 (fix broken end of input rule $ with captures) – the latter bug was inadvertently introduced in version 4.3. See the changelog 4.3.1 (2025-12-01).
Release 4.3¶
This release adds -Wdeprecated-eof-rule warning and improves
compile-time performance.
Upcoming changes to the end-of-input rule.
Normally, if there’s a conflict between two or more rules
(meaning that they both match the same string) re2c chooses the first rule
based on their position in the input file. The same goes for reused blocks:
their rules are inserted at block start for use:re2c blocks, or at the
point where !use directive is specified.
Special rules (such as the default rule * and the end of input rule $)
have different precedence and inheritance order. A block is not allowed to
specify the same special rule more than once, and inherited special rules have
lower priority compared to the block’s own special rules.
In the future re2c will support generalized end of input symbol $ as part
of a normal rule (rather than a special rule). At the moment the only supported
form is a standalone rule $ { ... }, but in the future re2c will support
cases like [a] $ | [b] { ... } etc. To allow this, $ needs to have
position based precedence and inheritance order. However, it will be a breaking
change for cases that have conflicting rules.
This release prepares for the migration: it does not change behaviour yet, but
it add a warning -Wdeprecated-eof-rule for the cases that will be broken
in the future. For now the warning can be disabled with
-Wno-deprecated-eof-rule, however it is strongly recommended to fix it,
as the warning will be turned to error in the future, and the generated code
will change.
See #525 for more details.
Compile-time performance improvements. Internal TDFA construction code has been optimized: it now avoids some redundant copying, making the determinization process ~1.5 times faster for some Unicode scanners. The algorithm itself wasn’t changed. See #544 for more details.
See the changelog: 4.3 (2025-06-30).
Release 4.2¶
This release adds a new backend for Swift,
a relative form of computed goto for C/C++,
exception specifications for recursive functions
and some new benchmarks.
Swift backend.
Code generation into Swift is now supported using the recently added
syntax files. It can be enabled via
re2swift binary or the new option --lang swift. See
Swift examples on the playground
and the full Swift manual for details.
Relative computed goto.
Computed goto is a feature that is currently supported only by the C/C++
backend. This release adds (#533)
a new form of computed goto which computes jump targets using offsets
relative to a base label rather than absolute label. This makes the generated
code easier to use in shared libraries, as it reduces the number of dynamic
relocations, and by consequence, allows the data stored in computed goto
table to be read-only.
See https://gcc.gnu.org/onlinedocs/gcc/Labels-as-Values.html for details.
The new behaviour can be enabled with option --computed-gotos-relative
or configuration re2c:computed-gotos:relative (or an alias
re2c:cgoto:relative). Beware of a related
GCC bug.
Exception specifications.
A new configuration re2c:yyfn:throw allows the user to specify
exceptions thrown by the YYFN function. By default it’s an empty string,
meaning no exception specification. The new configuration is available in syntax
files in the form of .yyfn.throw conditional and throw variable in the
function code templates code:fndecl and code:fndef.
The primary motivation for this was the use in the Swift backend
(#540).
For a full list of changes and bug fixes see the changelog
4.2 (2025-04-23).
As always, thanks to all contributors, especially
ScrelliCopter who implemented the Swift
backend and caffe3 who whorked on computed
goto!
Release 4.1¶
This release adds actions, a few backend-specific improvements in code generation and a bunch of bug fixes. Benchmark code has been reworked in preparation to add multi-language benchmarks in the future.
Actions.
Actions are user defined blocks of code that
can be attached to various parts of the generated code. This release adds three
new actions. First, the !entry action is executed at the lexer entry, which
can be used to emit set up code (it is similar to the zero condition < >,
but the action is more flexible: it can be set individually per condition, and
it allows one to bypass the initial condition dispatch and jump directly to the
start of each condition). Second, the !pre_rule action is executed
immediately before semantic action for each rule in the current block or
condition. Third, the !post_rule action is like the previous one, except
that it is executed immediately after each semantic action.
Backend-specific improvements.
OCaml backend now uses unsafe_get instead of get as the default
YYPEEK implementation – the generated lexer already performs end of input
checks, so the bounds checks in get are redundant.
Zig backend now uses const for yych declaration in
--recursive-functions mode, as the variable is not mutated and declaring it
as a variable is an error in the recent compiler versions.
For a full list of changes and bug fixes see the changelog 4.1 (2025-02-16). As always, thanks to all contributors, especially eilvelia for great bug reports and discussion!
Release 4.0.2¶
This is a minor release that fixes CMake build system bug
#515
(language-specific binaries erroneously defaulted to generating code for C, e.g.
re2rust worked in the same way as re2c if --lang rust option wasn’t set).
There are also numerous playground improvements.
See the changelog 4.0.2 (2024-12-11) for details.
Release 4.0.1¶
This is a minor release that adds missing doc sources to the release tarballs (thanks to jcfp for the bug report) and has a few changes in the build system and C/C++ examples. See the changelog 4.0.1 (2024-11-25) for details.
Release 4.0¶
This release adds support for eight new languages (D, Haskell, Java, JavaScript, OCaml, Python, V, Zig). Code generation subsystem has been completely rewritten using syntax files — a technique for describing language backends. With so many new languages re2c now has a more generic meaning: Regular Expressions to Code rather than Regular Expressions to C. A new code generation model based on recursive functions has been added to enable support of functional languages. Much effort went into simplifying user interface: the former default API is now called simple API and supported for backends other than C/C++, and there is a new record API for cases when lexer state needs to be stored. Capturing groups can now be used with variables instead of arrays. Last but not least, re2c now has an online playground.
Syntax files.
Previously language-specific logic was hardcoded into re2c. This made it difficult to add new languages or tweak code generator for existing ones, as it required patching re2c and upstreaming the changes, or else maintaining a fork. Now all language-specific logic has been moved to syntax files — declarative configuration files that can be supplied by the user and don’t require rebuilding re2c. Adding support for a new language is as simple as writing a syntax file for it. One can partially override an existing syntax file or completely redefine everything from scratch, if needed. For examples of syntax files see include/syntax subdirectory.
API changes.
For a long time C/C++ was the only backend that supported default API, because
pointer-like semantics of YYCURSOR and other primitives was hardcoded into
re2c. With the addition of syntax files, it is now possible to define
API flavours individually for each language. For languages that don’t have
pointer arithmetic YYCURSOR and others should be defined as indices rather
than pointers, and a new primitive YYINPUT should be used to define the
indexed character sequence. The former default API is now called simple API to
avoid confusion, as some languages historically default to generic API. Simple
API is implemented for all languages except Haskell and OCaml, and it’s enabled
by default for C, D, Java, JavaScript, Python, V and Zig. It can be explicitly
enabled with --api simple option or re2c:api = simple configuration.
There’s also a new record API enabled
with --api record option and re2c:api = record configuration that should
be used in cases when lexer state needs to be stored in some form of a record (a
struct, a class, an object — whatever it’s called in the target language).
This is usually the case when YYFILL is enabled, as it needs to update lexer
state in a subroutine. Record API defines all operations via a single primitive
yyrecord — a record with fields for YYCURSOR and other primitives (as
needed). The names of the fields are language specific, but for most languages
they default to lowercase equivalents of the primitives (e.g. yycursor for
YYCURSOR), and they can be changed with the corresponding configurations.
The name of the record itself can be changed with re2c:yyrecord
configuration. See examples
that use record API.
Some options and configurations have been renamed (old aliases still work),
see the changelog for
details. Configurations that have define: or variable: parts now
have shorter aliases without these parts (e.g re2c:YYCURSOR instead of
re2c:define:YYCURSOR and re2c:yych instead of re2c:variable:yych).
The goal of this change is to make the naming scheme more consistent, as
wide-scope define: and variable: prefixes were in conflict with
narrow-scope prefixes like tags:, cond:, yych: etc.
Recursive functions.
This release adds a new code model based on recursive functions (enabled with
--recursive-functions option). Previously re2c supported two code models.
One is based on goto and labels (enabled with --goto-label option); it
generates efficient code, and it’s the best option for languages that support
goto statement. The other model is based on state-switch inside of a loop
(enabled with --loop-switch option); it is for languages that don’t have
goto, but do have variables and loops. However, functional languages like
Haskell don’t have that — they have immutable bindings instead of variables
and recursion instead of loops. Therefore a third code model was needed. Some
languages support all three models, and some support just one (supported models,
as well as the default one, are defined by the syntax files).
Captures with variables.
Previously re2c always used POSIX-style yypmatch array to store submatch
results with capturing groups (--posix-captures and --leftmost-captures
options). However, it may be more convenient to use a scalar variable for each
parenthesis instead of an array (some languages don’t even have mutable arrays
in the standard library). This release adds --posix-captvars and
--leftmost-captvars options that store submatch results in variables with
autogenerated names <prefix>l<k> and <prefix>r<k> for k-th capturing
group, where <prefix> is the value of re2c:tags:prefix configuration.
There’re also new block types svars and mvars that are exactly like
stags and mtags, except that they are expanded for the variables used
in semantic action, not for the intermediate tag variables.
Block start/end markers.
For a long time re2c supported Flex-style block start/end markers %{ and
%}. Now this syntax is extended to all kinds of blocks, e.g. %{local for
a local block /*!local:re2c, %{rules:foo for a named rules block
/*!rules:re2c:foo, %{getstate:x:y:z for a special block
/*!getstate:re2c:x:y:z, etc. The new syntax is primarily intended for
languages that don’t have C-style multiline comments /* ... */.
Warnings on by default.
Warnings that indicate serious issues with the code are now enabled by default.
This includes
-Wundefined-control-flow,
-Wsentinel-in-midrule,
-Wunreachable-rules,
-Wuseless-escape,
-Wswapped-range and
-Wcondition-order.
If needed, each of them can be disabled with an explicit -Wno-* option.
To enable less important warnings, use -W.
A new warning -Wundefined-syntax-config has been added. It warns when a
syntax config does not define some configurations — fix it by defining them or
explicitly setting them to <undefined>.
Online playground Thanks to PolarGoose, re2c now has an online playground that allows one to load examples for all languages, edit, compile and share the code online.
For a full list of changes and bug fixes see the changelog 4.0 (2024-11-19). As always, thanks to all contributors!
Release 3.1¶
The main focus of this release has been on internal rather than user-facing changes. The codebase has been cleaned up and migrated to C++11, and the codegen subsystem has undergone considerable simplification and rewrite. Some new features have been added to improve submatch extraction with capturing groups (see below for more details).
Capturing groups.
Since release 1.0, re2c supported two ways of submatch extraction: tags with
leftmost greedy semantics (enabled with --tags option or re2c:tags
configuration) and capturing groups with POSIX longest-match semantics (enabled
with --posix-captures option or re2c:posix-captures configuration).
Capturing group syntax is traditionally used in regular expression libraries, so
it is preferable for some users. However, they found it
problematic to use with large
regular expressions: compile times are increased due to the complex POSIX
disambiguation algorithm, and the generated code is bloated, as every pair of
parentheses is a capturing group and it requires runtime operations to extract
submatch boundaries. This release addresses both problems.
First, it adds --leftmost-captures option and re2c:leftmost-captures
configuration that allow using capturing group syntax with leftmost greedy
semantics. Second, it adds new syntax (! ...) for non-capturing groups, so
that the user can mark only a few selected groups for submatch extraction, and
avoid unnecessary overhead on other groups. It is also possible to flip defaults
with --invert-captures option or re2c:invert_captures configuration, so
that (...) is a capturing group and (! ...) is a non-capturing one.
TDFA paper and removal of experimental algorithms. In previous releases, re2c added a few experimental algorithms for research purposes (alternative types of automata for submatch extraction, different approaches to POSIX disambiguation and epsilon-closure construction, etc.). All these algorithms have been shown less efficient in the final TDFA paper (see the benchmark results). In this release the following experimental algorithms have been removed: staDFA, TDFA(0), backwards-matching, Kuklewicz POSIX disambiguation and GTOP shortest path finding. The corresponding options are deprecated: they are still accepted for backwards compatibility, but do nothing. This is part of the general effort to keep re2c codebase simpler and easier to maintain.
Codebase improvements. Most of the work in this release has been dedicated to simplifying the codebase and migrating it to C++11 standard. Codegen subsystem in particular has been reorganized in four well-defined phases (analyze, generate, fixup, render) and separated from parsing phase. Errors are now handled in a uniform way by checking return codes and propagating them up the call stack. Memory allocation has been improved with the use of slab allocators instead of global free lists. Bison parsers now use pure API. Recursive functions that potentially cause stack overflow have been rewritten in iterative form, and re2c test suite now runs with 256K stack limit on CI. Finally, code style has been unified across the codebase.
Build system. This release adds minimal Bazel integration: it is now possible to use re2c as a tool in other projects with Bazel build systems (see commit 3205c867 for a usage example). This is not intended as a new build system alongside Autotools and CMake; Bazel integration is minimal and does not support developer build features like bootstrap, documentation, etc.
CI improvements. Continuous testing on GithubActions is more extensive now: it covers both build systems (Autotools and CMake) as well as special validation modes, such as ASan, UBSan and Valgrind.
For a full list of changes and bug fixes see the changelog 3.1 (2023-07-19). As always, thanks to all contributors, especially Sergei Trofimovich, Doug Cook and Marcus Boerger!
Release 3.0¶
This release adds Rust support, a uniform naming scheme for options and configurations, small improvements in code generation and a few bug fixes.
Rust backend.
It has been on the wish-list for quite a while, but the real work has started on
#372 with
raekye doing the initial implementation and
pmetzger porting the first examples.
After a few weeks of brainstorming on irc.oftc.net
(#re2c), followed by a few months of work, now the Rust backend is fully
implemented and ready to use.
See the re2rust manual with examples.
The main difficulty with Rust is that it has no goto statement, which makes
the usual code generation approach impossible. Normally re2c uses goto-label
approach: DFA states are blocks of code with labels, and transitions are
goto statements. For Rust a different approach is needed: a DFA is
represented with a switch on a numeric state variable, where each state is a
separate case. Transitions set state variable to the target state index and loop
to the start of the switch. The loop-switch approach can be used for other
languages as well, therefore it has been added as an option --loop-switch
(available for all backends and mandatory for Rust).
The new approach is different enough to require multiple changes in code
generation. In loop-switch mode it is impossible to jump into the middle of a
state bypassing the skip statement, so the --eager-skip option is enforced,
which moves skip statements to transitions. With conditions it is impossible to
jump between different blocks, so DFAs for all conditions are merged into one
switch, and condition numbers are the indices of the initial DFA states. In
storable state mode it is impossible to jump from the YYGETSTATE switch to a
DFA state, therefore a separate getstate:re2c detached from the lexer block
is not supported. Most of these implementation details are hidden from the user.
Generic API is set by default
for Rust, as the use of pointer arithmetic is unsafe and generally discouraged.
The YYPEEK operation is automatically wrapped in unsafe because it should
avoid bounds checks, which are done by the lexer in a
more efficient way.
To get rid of the automatic unsafe wrappers use option --no-unsafe or
configuration re2c:unsafe on a per-block basis (this can help to verify
lexer behavior in debug mode, for example).
Initialization of yych in the generated code is prefixed with
#[allow(unused_assignments)]. In fact initialization is not needed (yych
is always set before it is used), but the Rust compiler cannot figure it out in
cases with complex control flow and emits errors if initialization is missing.
Rust backend and the new re2rust binary are enabled by default, but the
build can be configured with --enable-rust, --disable-rust Autoconf
options or -DRE2C_BUILD_RE2RUST CMake option.
New aliases.
Some configurations that have been added over the years are at odds with the
general naming scheme. For example, most of condition-related configurations
have re2c:cond: prefix, as in re2c:cond:goto or re2c:cond:divider,
but for some reason re2c:condprefix has no column after cond. It is
illogical, and it would be better to have re2c:cond:prefix instead. This
release adds a bunch of such aliases. Of course, the old names still work, and
there is no plan to remove them (the change does not break existing code).
Likewise some options have new aliases. For a full list see the
changelog.
Code generation.
The changes in code generation are minor. The main difference is in the state
enumeration: states without incoming transitions do not have numbers anymore.
This was required for the loop-switch approach, so that switch cases can have
consecutive labels. Other code generation changes include removal of unused
YYPEEK statements and slightly different formatting.
For a full list of changes and bug fixes see the changelog 3.0 (2022-01-27). Huge thanks to all contributors, especially raekye and pmetzger!
Release 2.2¶
This release adds scoping rules and improves code sharing between re2c blocks. It brings in a bunch of new features, most importantly named blocks, local blocks, scoped directives and the ability to include arbitrary blocks in the middle of another block. Much work has been done on improving testing and continuous integration.
Local blocks.
This release adds a new kind of blocks: /*!local:re2c ... */, which are
exactly like the usual /*!re2c ... */ blocks, except that they do not add
their named definitions and configurations to the global scope. The contents of
a local block are not visible outside of the block and do not affect subsequent
blocks.
Named blocks.
Previously all re2c blocks were anonymous. Now it is possible to give block a
name: for example, /*!re2c:woot42 ... */ defines a global block named
woot42. The name can be used to refer to this block in other parts of the
program (for example in
directives). Rules blocks can
have names as well: a block /*!rules:re2c:woot42 ... */ can be mentioned in
a use block /*!use:woot42 ... */ or in a use directive !use:woot42;.
Use blocks cannot have their own name; if you need to have a named block that
reuses another block, do that with the new !use directive.
Block lists in directives.
Previously re2c directives
such as max:re2c, stags:re2c, getstate:re2c etc. were global: they
accumulated the information across all blocks in the file. Now it is possible to
specify a list of colon-separated block names in each directive: for example
/*!<directive>:re2c:<name1>:<name2>... */ where <name1>, <name2> and
so on are the names of re2c blocks defined somewhere in the file. This allows
one to have scoped directives, and also multiple directives per file for
different groups of blocks. For example, if the file defines named blocks
foo, bar and baz, one can define all s-tag variables in blocks
foo and baz with a directive /*!stags:foo:baz ... */.
In-block use directive.
Now it is possible to use a block in
the middle of another block: for example, a rules block
/*!rules:re2c:woot42 ... */ can be used in the middle of another block with
a statement !use:woot42;. Rules, named definitions and configurations of the
used block are added to those of the current block. The new use directive is
more flexible than the old /*!use:re2c ... */ block, because there is no
limitation on the number of used blocks, and they don’t have to be used at the
beginning of a block.
In-block include directive.
The existing /*!include ... */ directive now has an
in-block variant. For example,
!include "x/y/z.re"; includes a file x/y/z.re in the middle of a block.
The in-block include directive works in the same way as the out-of-block one:
the contents of the file are inserted verbatim in place of the directive.
Configurable directives.
More directives can now be
customized with configurations that define the form of the generated code.
Directives max:re2c and maxnmatch:re2c now have an optional format
configuration that accepts a template string with interpolated variable
@@{max} (or just @@ for short), for example
/*!max:re2c format="int maxfill = @@;"; */ would generate code
maxfill = <N>; where <N> is the YYMAXFILL value.
Directive types:re2c now has optional configurations format and
separator: the former accepts a template string with interpolated variables
@@{cond} and @@{num} (the name and numeric index of each condition), and
the latter specifies the glue text used to join different format pieces
together.
Testing. Serghei Iakovlev ported the old and hairy testing script from Bash to Python 3. The new script covers more platforms and is much faster than the old one (and also easier to debug and modify).
See the changelog 2.2 (2021-08-01) for details. As always, a big thanks to all contributors!
Release 2.1.1¶
This is a minor release that adds a missing file to the release tarballs (thanks to david_david for the bug report). See the changelog 2.1.1 (2021-03-27) for details.
Release 2.1¶
This release adds continuous integration with GitHub Actions, portability improvements, benchmarks, depfile generation and bugfixes.
GitHub Actions CI. Serghei Iakovlev has added continuous integration with GitHub Actions for Linux, macOS and Windows platforms. Now every change in re2c gets build and tested in various configurations on all three platforms, which (hopefully!) leads to fewer bugs and better support for these platforms. GitHub Actions complement the existing Travis CI.
Benchmarks.
A lot of work has been done on adding infrastructure for benchmarks. Previously
re2c had some benchmarks, but they were not integrated into the build system,
and as a result somewhat difficult to build and run. Now there is a new
benchmark subsystem, which includes three groups.
The first group contains AOT-compiled benchmarks (a.k.a. lexer generators):
regular expressions that are compiled ahead of time to C code, which is further
compiled to native code. The currently supported generators are re2c, ragel and
kleenex.
The second group contains JIT-compiled benchmarks: library algorithms that are
based on deterministic automata.
Finally, the third group contains interpreted benchmarks: library algorithms
that are based on non-deterministic automata.
Benchmarks are fully integrated in both build systems (they are enabled with
Autotools options --enable-benchmarks, --enable-benchmarks-regenerate
and CMake options -DRE2C_BUILD_BENCHMARKS, -DRE2C_REGEN_BENCHMARKS).
All benchmarks are regularly built and ran on CI.
There is also a script
for rendering benchmark results as bar charts.
For lexer generators, benchmark results show that re2c-TDFA(1) and ragel are the fastest algorithms. Their performance is very close, but in non-deterministic cases ragel gives incorrect results due to its inability to remember multiple parallel versions of one tag. On the other hand, kleenex programs are much shorter and easier to read.
Dependency files.
This release adds a --depfile option that allows one to generate dependency
(.d) files. This is needed in order to track build dependencies in the presence
of /*!include:re2c*/ directives. The generated depfiles have the same format
as the ones generated with GCC -MF option.
There are also a few other improvements and bugfixes, see the full changelog 2.1 (2021-03-26) for details.
A big warm thank you to all the people who contributed to this release!
Release 2.0.3¶
This is a minor bugfix release. It fixes an issue when building re2c as a subproject of another CMake project (thanks to Ivo Hanak for the bugreport). See the changelog 2.0.3 (2020-08-22) for details.
Release 2.0.2¶
This is a minor bugfix release.
It makes two changes.
First, re2go is now built by default (can be turned off with
--disable-golang for Autotools and -DRE2C_BUILD_RE2GO=no for CMake).
Second, CMake build files are now packaged into release tarball.
See the changelog 2.0.2 (2020-08-08) for details.
Release 2.0.1¶
This is a minor release that fixes re2c version (as output by re2c -v) for
the CMake build system. Thanks marryjianjian
for the bug report!
See the changelog 2.0.1 (2020-07-29) for details.
Release 2.0¶
This release adds a Go code generation backend, an alternative CMake build system, free-form generic API, improvements in reuse mode and start conditions, and bugfixes in EOF rule implementation.
Go backend.
The new Go code generation backend can be used either with a --lang go re2c
option, or as a standalone re2go binary (which is identical to re2c with
--lang go set by default).
The documentation has been split into separate manpages for
re2c and
re2go; they are
generated from the same text, but have language-specific examples.
The re2go binary and manpage need to be enabled explicitly with a configuration
parameter --enable-golang for Autotools or -DRE2C_BUILD_RE2GO=yes for
CMake.
Unlike C, Go does not have pointer arithmetics, therefore re2go programs use
integer indices instead of pointers and have
generic API enabled by default.
Almost all re2c features have been ported to re2go, with the exception of code
generation options like --computed-gotos and --case-ranges that
need unsupported language features.
Behind the scenes adding a new backend required a
full rewrite
of the code generation subsystem and quite a bit of work on documentation
and testing.
Thanks to meme for
discussing the idea and
providing an early implementation prototype.
Feedback from the Go community is welcome!
CMake build system. Thanks to ligfx for adding a CMake-based build system. This has been discussed multiple times in the past, and a few attempts at an implementation have been made, but ligfx was the first to contribute a full working implementation. The existing Autotools-based build system continues to be used and maintained for the foreseeable future. In fact, both build systems are continuously tested on Travis CI. See the build instructions page for more details.
Free-form generic API.
Generic API now supports
two styles: function-like style is
enabled with re2c:api:style = functions;, and free-form style is enabled
with re2c:api:style = free-form;.
Previously only the function-like style was supported, and free-form style
could be enabled for a few selected APIs with configurations like
re2c:define:YYFILL:naked, etc.
Free-form style allows to define API primitives as arbitrary strings of code
with interpolated arguments of the form @@{name}, or optionally just @@
if there is a single argument. The @@ marker can be redefined with
re2c:api:sigil configuration.
Improved reuse mode and start conditions.
The restriction on not using normal (non-conditional) blocks with
-c, --start-conditions option has been removed: now it is possible to have
both conditional and normal blocks. The switch on conditions is now generated
for every block rather than once per file, which allows to have multiple lexers
in one file.
The combination of -r, --reuse option with -c, --start-conditions and/or
-f, --storable-state options
now uses correct
block-local options instead of global options in condition and state switch,
and re2c now generates
unique labels
in each reuse block.
Fixes in EOF rule. A bug that caused missing fallback states with EOF rule has been fixed. Re2c no longer generates overlapping labels when EOF rule is used with multiple blocks.
Developer changes.
The way re2c bootstraps itself
has been simplified:
instead of always trying to regenerate lexer files if the re2c binary exists in
the build directory, re2c now does this only when configured explicitly with
--enable-lexers for Autotools or -DRE2C_REBUILD_LEXERS=yes for CMake.
This configuration requires passing an explicit RE2C_FOR_BUILD variable that
contains a path to the re2c executable that will be used to regenerate lexers.
The new bootstrapping scheme allows to avoid build problems caused by
dynamically changing dependency graph, as well as hard-to-recover errors when a
bad re2c build was used to rebuild itself in a vicious loop.
Another developer-visible change is a
rework of the testing framework,
which now uses in-line comments instead of hard-coding options in test filenames.
Backwards incompatible changes. In a few rare/undocumented cases re2c behavior has been changed in a way that may break existing code:
Generic APIs
YYSHIFT/YYSHIFTSTAG/YYSHIFTMTAGhave been added. Their meaning is to shift the cursor/tag position by a specified offset. The new APIs enable fixed-tags optimization with generic API, which is becoming more important as the generic API is getting used more often. Programs that use both generic API and tags or POSIX capturing groups may need to define the new APIs.Generic APIs
YYSTAGPD/YYMTAGPDhave been removed. They were used only with the recently added experimental--stadfaoption, and the removal is unlikely to break any existing code.In reuse mode configurations like
re2c:define:YYCTYPEare no longer reset in each use block. The old behavior was kept only for backwards compatibility. It has caused confusion and inconvenience, as the configurations had to be repeatedly defined in each use block.The
re2c:flags:type-headeroption now treats the header filename as relative to the output directory. The undocumentedre2c:flags:outputoption has been removed.Some internal labels have been renamed, in particular the
yyFillLabelprefix has been replaced withyyfill. This should not break any well-formed code, as these labels are not part of the user interface. Programs that relied on the old label names may restore them with there2c:label:yyFillLabelconfiguration.
As always, a warm thank you to all the people who contributed to this release, including ligfx, meme, ryandesign, fanf2, samebchase and trofi. :)
See the changelog 2.0 (2020-07-20) for details.
Release 1.3¶
The bulk of the work in this release was concentrated on implementing an
experimental submatch extraction algorithm. The new algorithm is based on
staDFA: another type of automaton described in the paper “staDFA: An Efficient
Subexpression Matching Method” by Mohammad Imran Chowdhury (2018).
Like TDFA, staDFA performs operations on variables that hold submatch positions
during the matching process. The main difference between the two automata types
is that TDFA associates variable operations with
transitions, while staDFA puts them in states. Now that we have an experimental
implementation of staDFA in re2c, it is possible to compare its performance
against TDFA. The initial experiments have shown that on average staDFA is
slower and larger than TDFA(1): it has more variable operations and more states.
It still remains to run proper benchmarks and formalize the modifications to
the original algorithm that we had to make for correctness and performance.
The new staDFA algorithm is enabled with --stadfa option.
This release adds a new warning -Wsentinel-in-midrule that warns the user in
the case when the sentinel symbol occurs in the middle of the rule – this may
cause reads past the end of buffer, crashes or memory corruption in the
generated lexer. Complimentary to the warning there is a new configuration
re2c:sentinel that allows to specify which symbol is used as a sentinel
(by default re2c assumes NULL). It this configuration is used, then
-Wsentinel-in-midrule is an error.
Some work has been done on reproducible builds.
As usual, thanks to all the people who contributed to this release (including Chris Lamb, jcfp and Ondřej Čertík)! See the changelog 1.3 (2019-12-14) for details.
Release 1.2.1¶
This is a minor release that improves some of the features introduced in 1.2.
First, it is now possible to reset re2c:eof configuration to the
default value by setting it to -1. Second, re2c now installs standard
include files to $(datadir)/re2c/stdlib, where $(datadir) is
/usr/share by default (but can be configured otherwise). When looking for
include files, re2c automatically tries this directory — there is no need
to add it manually with -I.
Both issues have been reported by Wesley W. Terpstra. Thank you!
See the changelog 1.2.1 (2019-08-11) for details.
Release 1.2¶
This release adds a handful of useful features and finalizes two-year research effort on POSIX disambiguation.
First and foremost, end of input rule
has been added to re2c. It is a new method of checking for the end of input,
which aims at being both generic and simple to use. Historically re2c has a
number of ways to handle
EOF situation. The simplest and the most efficient method is
using a sentinel symbol, but it
has limited applicability. The most widely used and generic method is
bounds checking with padding,
but it is rather complex and requires input buffering.
Finally, it is possible to define custom EOF handling methods
by using the generic API. However,
such methods are not necessarily correct and are likely to be slower than other
methods. The new method, EOF rule, tries to combine the simplicity and
efficiency of the sentinel symbol and the generality of bounds checking.
Essentially, all the user is required to do is to specify an arbitrary “fake”
sentinel using re2c:eof configuration (zero is usually a good choice), to
define a special EOF rule $, and to make sure that the fake sentinel is
always the last symbol in the input buffer. The lexer will then run without end
of input checks until it hits the branch corresponding to the fake sentinel, at
which point it will perform additional bounds checking. If indeed it is the end,
the lexer will try to get more input. If this attempt fails, the lexer will
either rollback to the last matched rule (or the default rule, if it has
consumed some input but did not match), or else it will go to EOF rule.
Depending on each particular case and the choice of sentinel, the performance of
EOF rule may be slightly better or worse than bounds checking with padding.
See the user manual for more details and examples.
Another important new feature is the possibility to include other files. Re2c provides a directive
/*!include:re2c "file.re" */, where file.re is the name of the included
file.
Re2c looks for included files in the directory of the including file and in the
include locations, which can be specified with -I option. Include files
may have further includes of their own. Re2c provides some predefined include
files that can be found in the include/ sub-directory of the project. These
files contain useful definitions and form something like a standard library
for re2c. Currently there is one available include, unicode_categories.re.
Re2c now allows to generate header file
from the input file using option -t --type-header or
re2c:flags:t and re2c:flags:type-header configurations and the newly
added directives /*!header:re2c:on*/ and /*!header:re2c:off*/.
Header files may be needed in cases when re2c is used to generate definitions
of constants, variables and structs that must be visible from other translation
units.
Re2c can now understand UTF8-encoded string literals and character classes in
regular expressions. By default, re2c parses regular expressions like
"∀x ∃y" as a sequence of 1-byte ASCII code points
e2 88 80 78 20 e2 88 83 79 (hexadecimal), and the users have to escape
Unicode symbols manually: "\u2200x \u2203y". This is not what most users
would expect, as demonstrated by multiple issues on the bugtracker. The new
option --input-encoding <ascii | utf8> allows to change the default
behavior and parse "∀x ∃y" as a sequence of 4-byte Unicode code points
2200 78 20 2203 79 (hexadecimal). Note that the new option affects only
parsing, and not the code generation.
Re2c now allows to mix reusable blocks
with normal blocks when -r --reuse option is used. This is very useful in
cases when the input file contains many re2c blocks, and only some of them need
to be reused (a good example is re2c own lexer, which has to use certain rules
twice in order to generate ASCII and UTF8 lexer variants for
--input-encoding <ascii | utf8> option).
It is now possible to specify location format in re2c-generated messages with
--location-format <gnu | msvc> option. As one might guess, possible
arguments are GNU location format filename:line:column: (the default) and
MSVC format filename(line,column). This option might help IDE users.
Another new option is --verbose — it prints a short “success” message in
case re2c exits successfully.
Flex compatibility mode (enabled with -F --flex-support option) has been
improved: parsing errors and incorrect operator precedence in some rare cases
have been fixed. Historically re2c allows to mix flex-style code with re2c-style
code, which creates certain difficulties for the parser. Such difficulties can
be resolved by passing parts of the parser context to the lexer.
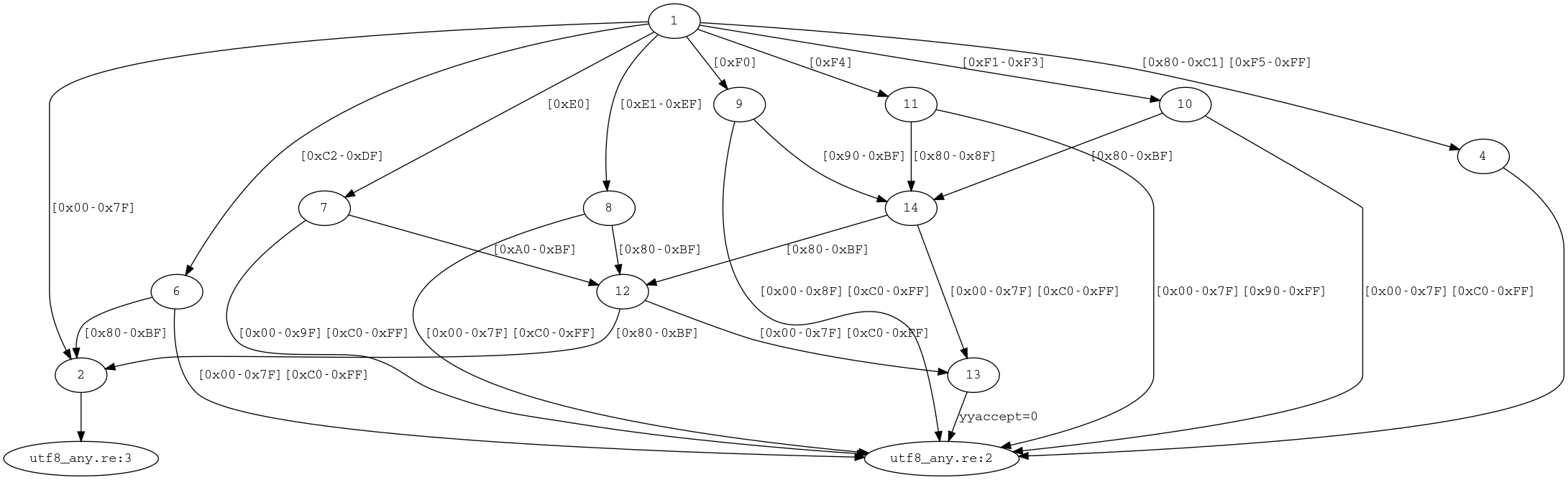
The difference operator / is now applied to its operands before encoding
expansion. Re2c supports difference only for character classes, and encoding
expansion in case of a variable-length encoding may transform even a simple
character class into a complex graph (see
the graph for [^] in UTF8 for example).
Applying expansion after difference makes / applicable in more cases.
{kind=link}
Re2c now generates the output file atomically: it first creates a temporary file and writes the generated output into it, and then renames the temporary file to the output file.
Documentation has been rearranged and updated, and the website has been fixed to look somewhat better on mobile devices (hopefully).
From developers standpoint, re2c now has better debugging capabilities. Debug
code has been moved in a separate subsystem and is no longer built in release
binaries (debug builds are enabled with --enable-debug configure option).
New debug options and passes have been added.
This release has taken almost a year, mostly because of the time needed to
formalize the extended algorithm for POSIX disambiguation and write a formal
paper Efficient POSIX Submatch Extraction on NFA.
The algorithms described in the paper are implemented in an experimental
library libre2c. The library is intended as a playground for experiments
and research, not a replacement for existing libraries like RE2. Having re2c
as a library is convenient for benchmarking, testing and creating bindings to
other languages.
To build the library and benchmarks, configure re2c with --enable-libs option.
Many people have contributed to this release. Angelo Borsotti co-authored the paper; his hard work has revealed multiple shortcomings and deficiencies in the algorithms used in re2c. Henri Salo helped with fuzz-testing re2c using the American Fuzzy Lop. Denis Naumov helped with Windows portability issues. Sergei Trofimovich fixed a number of bugs; he and Serghei Iakovlev helped with the Travis CI infrastructure. Wesley Terpstra used re2c in the open-source wake build tool. Many thanks to them and all the others who contributed to this release!
A lot of bugs have been fixed. See the changelog 1.2 (2019-08-02) for details.
Release 1.1.1¶
This is a minor bug-fix release.
It fixes a crash with -V --vernum option.
The crash was reported and fixed by Mike Gilbert,
and later rediscovered by Daniel J. Luke and Perry E. Metzger.
Sergei Trofimovich made a unit test, as the -V --vernum option has already caused some troubles in the past.
See the changelog 1.1.1 (2018-08-30) for details.
Thanks everyone!
Release 1.1¶
This release doesn’t bring in any serious user-visible changes;
most of the work concentrated on the internal POSIX disambiguation algorithm
used for submatch extraction with --posix-captures option.
The old algorithm, introduced in release 1.0, was based on the work of Chris Kuklewicz
(outlined on this haskell wiki page
and formalized in the paper Tagged Deterministic Finite Automata with Lookahead).
Kuklewicz algorithm was replaced with a totally different algorithm
based on the work of Satoshi Okui and Taro Suzuki (described in the paper
“Disambiguation in Regular Expression Matching via Position Automata with Augmented Transitions”, year 2013).
The main effort in this release was in developing proper theoretical foundations for the new algorithm.
As usual, there has been a couple of bug fixes.
See the changelog 1.1 (2018-08-27) for details.
Release 1.0.3¶
Yet another minor bug-fix release. It fixes a build failure on Mac OS X (thanks to Ryan Shmidt for the bug report). See the changelog 1.0.3 (2017-11-08) for details.
Release 1.0.2¶
This is another minor bug-fix release. It addresses some documentation issues (thanks to Ziris85 for the bug report). See the changelog 1.0.2 (2017-08-26) for details.
Release 1.0.1¶
This is a minor bug-fix release. It fixes a build failure on Mac OS X (thanks to ilovezf for the bug report). See the changelog 1.0.1 (2017-08-11) for details.
Release 1.0¶
This release is an important milestone in the history of re2c: it adds submatch extraction. It is a long-awaited feature; even as Peter Bumbulis released the first version of re2c back in 1993, he mentioned submatch extraction in his paper together with Donald D. Cowan “RE2C: a more versatile scanner generator” as a useful feature that soon should be added to re2c. It seemed back then that submatch extraction is relatively easy to implement; like many other useful extensions, it was deemed to be no more than syntactic sugar on top of canonical regular expressions.
As it turned out, this is not so: the problem of parsing with regular expressions is inherently more complex than recognition, and submatch extraction cannot be implemented using traditional DFA-based approach. Many authors studied this subject and developed algorithms suitable for their particular settings and problem domains. Some of them used NFA-based approach, others suggested algorithms based on multiple DFA or multiple passes over a single DFA. For re2c most of these algorithms are too heavyweight: they require complication of the underlying computational model and incur overhead even in simple cases.
However, one algorithm is outstanding in this respect: it is the algorithm invented by Ville Laurikari in 2000 and described in his paper “NFAs with Tagged Transitions, their Conversion to Deterministic Automata and Application to Regular Expressions”. Laurikari algorithm is based on a single DFA extended with a fixed number of registers; it makes one pass over the input string, works in linear time and the required space does not depend on the input length. But what is most important, the added complexity depends on submatch detalization: on submatch-free regular expressions Laurikari automaton reduces to a simple DFA.
When the work on submatch extraction feature started in early 2016, at first it seemed that Laurikari algorithm was still overly complicated. Re2c needed an algorithm that would support only partial submatch extraction, but the supported cases would be handled very efficiently. A lot of effort was spent on studying papers, and finally this lead to the development of a new algorithm. It soon became clear that the self-invented algorithm was in fact a special case of Laurikari algorithm, with one significant performance improvement: the use of lookahead symbol. Surprisingly, the original Laurikari algorithm has a strange deficiency: when recording submatches, the automata totally ignore the lookahead symbol and perform a lot of redundant operations that could be easily avoided. It was only logical to fix Laurikari algorithm. The new improved algorithm is described in the paper “Tagged Deterministic Finite Automata with Lookahead”
Submatch extraction in re2c comes in two flavors: POSIX-compliant capturing groups (with true POSIX semantics) and standalone tags that use leftmost greedy disambiguation. Both features require a number of new API primitives and configurations; and they are barely documented yet (though I managed to add a section in the manual). The paper cited above has some interesting benchmark results; articles and examples will follow in the nearest future. As usually, you may expect a number of small bug-fix releases in the 1.0.x series.
The following people contributed to this release:
Petr Skocik tidied up re2c documentation: fixed ubiquitous spelling errors and established synchronization system between the online documentation, manpage and help message displayed by re2c with
--helpoption.Sergei Trofimovich wrote a fuzzer that generates random regular expressions and checks them on input data generated with re2c
--skeletonoption. This fuzzer is most helpful; it has already found tens of bugs in the early implementation of submatch extraction. Sergei also helped me with testing re2c on numerous platforms and computer architectures.Abs62, asmwarrior, Ben Smith, CRCinAU, Derick Rethans, Dimitri John Ledkov, Eldar Zakirov, jcfp, Jean-Claude Wippler, Jeff Trull, Jérôme Dumesnil, Jesse Buesking, Julian Andres Klode, Paulo Custodio, Perry E. Metzger, philippschaefer, Ross Burton, Rui Maciel, Ryan Mast, Samuel006, sirzooro, Tim Kelly — all these people contributed bug reports, patches and feedback. Thank you!
Many thanks to the early user of the new features João Paredes for his patience and encouraging comments on the subject.
See the changelog 1.0 (2017-08-11) for details.
Release 0.16¶
This release adds a very important step in the process of code generation: minimization of the underlying DFA (deterministic finite automaton). Simply speaking, this means that re2c now generates less code (while the generated code behaves exactly the same).
DFA minimization is a very well-known technique and one might expect that any self-respecting lexer generator would definitely use it. So how could it be that re2c didn’t? In fact, re2c did use a couple of self-invented tricks to compress the generated code (one interesting technique is the construction of a tunnel automaton). Some of these tricks were quite buggy (see this bug report for example). Now that re2c does canonical DFA minimization, all this stuff is obsolete and has been dropped.
A lot of attention has been paid to the correctness of the DFA minimization. Usually, re2c uses a very simple criterion to validate changes: the generated code for all the tests in testsuite must remain the same. However, in the case of DFA minimization the generated code changes dramatically. It is impossible to verify the changes manually.
One possible verification tool is the skeleton feature. Because skeleton is constructed prior to DFA minimization, it cannot be affected by any errors in its implementation.
Another way to verify DFA minimization is by implementing two different algorithms
and comparing the results. The minimization procedure has a very useful property:
the miminal DFA is unique (with respect to state relabeling).
We used the Moore and the so-called table filling algorithms:
The Moore algorithm is fast, while table filling is very simple to implement.
The --dfa-minimization <moore | table> option that allows choosing
the particular algorithm (defaults to moore), but it’s only useful for debugging
DFA minimization.
A good side effect of messing with re2c internals is a significant speedup of code generation (see this issue for example). The test suite now runs twice as fast (at least).
See the changelog 0.16 (2016-01-21) for details.
Release 0.15.3¶
This release fixes multiple build-time and run-time failures on OS X, FreeBSD, and Windows. Most of the problems were reported and fixed by Oleksii Taran (on OS X) and Sergei Trofimovich (on FreeBSD and Windows). Thank you for your help!
Skeleton coverage has been improved.
See the changelog 0.15.3 (2015-12-02) for details.
Release 0.15.2¶
This release fixes a bug in the build system: it adds a missing dependency of the lexer on the bison-generated header (reported on Gentoo bugtracker). See the changelog 0.15.2 (2015-11-23) for details.
Release 0.15.1¶
This release fixes an error in the testing script (thanks to Sergei Trofimovich who reported the bug and suggested a quick fix). See the changelog 0.15.1 (2015-11-22) for details.
Release 0.15¶
This release started out in the spring of 2015 as a relatively simple code cleanup.
It focused on the following problem: re2c used to repeat the whole generation process multiple times. Some parts of the generated program depend on the overall input statistics; they cannot be generated until the whole input has been processed. The usual strategy is to make stubs for all such things and fix them later. Instead, re2c used to process the whole input, gather statistics, discard the generated output, and regenerate it from scratch. Moreover, each generation pass further duplicated certain calculations (for similar reasons). As a result, the code generation phase was repeated four times.
The problem here was not inefficiency: re2c is fast enough to allow the 4x overhead. The real problem was the complexity of the code: the developer has to think of multiple execution layers all the time. Some parts of code are only executed on certain layers and affect each other. Simple reasoning gets really hard.
So the main purpose of this release was to simplify the code and make it easier to fix bugs and add new features.
Very soon it became clear that some of the changes in code generation are hard to verify by hand.
For example, even a minor rebalancing of if and switch statements
may change the generated code significantly.
It was clear that re2c needed an automatic verification tool,
which lead to the idea of generating skeleton programs.
Meanwhile some work was done on adding warnings, updating the build system and fixing various bugs. A heart-warming consequence of the code simplification is that re2c now uses re2c more extensively: not only the main program, but also the command-line options, inplace configurations, and all kinds of escaped strings are parsed with re2c. Website has also been updated (feel free to suggest improvements).
See the changelog 0.15 (2015-11-22) for details.